Answer: 1.51
Case -1 Naive Pipeline
Since the cycle time is chosen as the largest stage time, so here the cycle time would be 20ns.
We are given that there is an interstage delay of 2ns after each stage. So effectively each stage would take 22ns. (Except the last stage of last instruction being executed)
So, let us choose the cycle time as 22ns
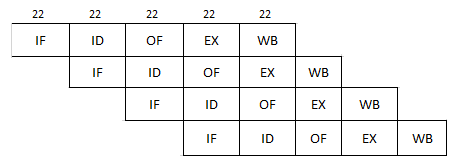
So, 20 instructions would take
[1st instruction x (20ns max stage time + 2ns stage delay) x total stages] +
[Rest 19 instructions x (20ns max stage + 2ns stage delay)] - 2ns (as last stage would not take buffering time)
[22 x 5] + [19 x 22 ] - 2
110 + 418 - 2
526
Case - 2 Efficient Pipeline
Here cycle time is chosen as the largest stage time (i.e of stage OF2), so here the cycle time would be 12ns.
We are given that there is an interstage delay of 2ns after each stage. So effectively each stage would take 14ns. (Except the last stage of last instruction being executed)
So, let us choose the cycle time as 22ns

So, 20 instructions would take
[1st instruction x (12ns max stage time + 2ns stage delay) x total stages] +
[Rest 19 instructions x (12ns max stage + 2ns stage delay)] - 2ns (as last stage would not take buffering time)
[14 x 6] + [19 x 14 ] - 2
84 + 266 - 2
348
Speedup is given by
Time taken without EP / Time taken with EP
526 / 348
1.51