I have read all comments and students have many doubts:
Let me clear it for you.
Doubt 1: visualization of twin pointers

Doubt 2: optimized algorithm with extra space as space is not a constraint.
| X |
106 |
108 |
110 |
| 101 |
X |
109 |
111 |
| 102 |
104 |
X |
112 |
| 103 |
105 |
107 |
X |
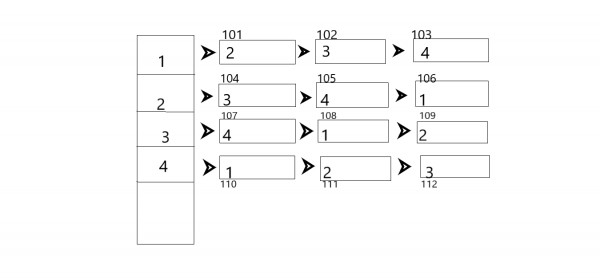
Lets us take an example of a complete graph ‘G’ with 4 nodes. The above diagram shows the linked list representation of G.
initialize a matrix add[1 to 4][1 to 4] keep a record of the address of each node while traversing for the first time.
Ex: If are starting from 1 then store ‘101’ in add[2][1]. Similarly, do for all nodes.
The time complexity of doing this step is O(m+n).
Now do 2nd traversing, and fill the address of twins for each node by using matrix.
Ex: for a node with 101 address fill the twin pointer with add[1][2] i.e 106.
The time for doing this will be O(n+m).
Overall time complexity = O(n+m)
Note: Here we are not traversing the matrix but only directly accessing specific elements of the matrix.
Doubt 3: Many students are using BFS and DFS. Honestly speaking you can use anything BFS, DFS, or simple traversing like I have used it. It will give the same time complexity.
Use of BFS is done to reduce the number of traversing of adjacency list as while filling the matrix u can fill twin pointers too at the same time.